
WhatsApp Chatbot Workflows: How to Architect Intelligent Automation That Scales to Millions of Conversations
Most WhatsApp chatbots fail not because of bad AI — but because of poorly designed conversation workflows. This deep-dive shows you exactly how to architect WhatsApp chatbot workflows that handle real-world complexity, scale to millions of sessions, and actually convert.
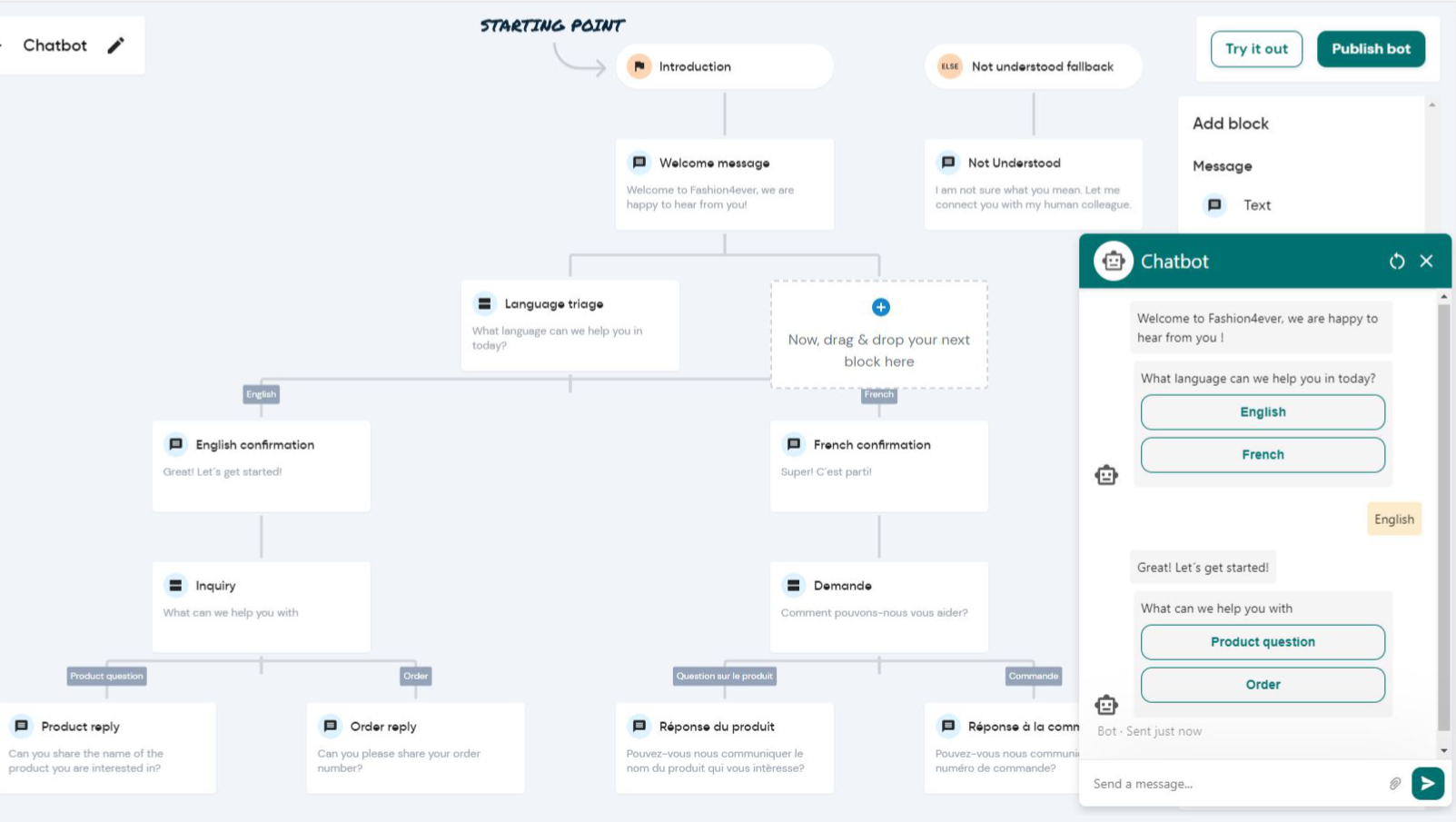
TL;DR Quick Answer: Effective WhatsApp chatbot workflows are not just about hooking an LLM to a messaging API. They require a robust conversation state machine, intent-routing logic, session persistence, graceful fallback handling, and a clear human-handoff protocol — all engineered to survive production load at scale. This article breaks down exactly how to build that.
Why Most WhatsApp Chatbot Workflows Break in Production
When businesses first explore WhatsApp chatbot workflows, the demo always looks clean. A user sends "Hi", the bot replies with a menu, the user picks an option, the bot returns a result. Everyone claps. Then you go live — and within 48 hours, users are sending voice notes, switching languages mid-conversation, abandoning sessions, replying out-of-order, and typing things like "nope that's wrong fix it" with zero context. The bot collapses.
The problem isn't the AI model. The problem is that the workflow was never designed for real humans. At Apargo, we've built and scaled WhatsApp chatbot workflows across industries — from e-commerce order management to healthcare appointment scheduling — and the patterns that survive production are very different from what gets demoed. This article is the engineering playbook we wish existed when we started.
The Core Architecture of Scalable WhatsApp Chatbot Workflows
Before writing a single line of bot logic, you need to understand the four foundational layers that every production-grade WhatsApp chatbot workflow must have:
- Message Ingestion Layer — Receives and normalizes incoming messages from the WhatsApp Business API (text, media, location, interactive replies)
- Session & State Management Layer — Tracks where each user is in the conversation, across multiple turns and even days
- Intent Resolution & NLP Layer — Determines what the user actually wants, regardless of how they phrased it
- Action & Response Orchestration Layer — Executes the right action (API call, database lookup, human handoff) and formats the correct response
Miss any one of these layers and your bot will feel broken — even if the AI responses are technically correct.
Layer 1: Message Ingestion and Normalization
The WhatsApp Business API delivers messages as webhook payloads. Your ingestion layer must be idempotent (handle duplicate deliveries), parse all message types, and normalize them into a consistent internal format before any business logic runs.
// Normalized message schema (TypeScript)
interface NormalizedMessage {
messageId: string; // WhatsApp message ID (for dedup)
sessionId: string; // Derived from phone number + business account
timestamp: number; // Unix ms
channel: 'whatsapp';
type: 'text' | 'image' | 'audio' | 'location' | 'interactive' | 'unknown';
text?: string; // Extracted text or transcription
payload?: Record<string, unknown>; // Raw type-specific payload
metadata: {
phone: string;
name?: string;
locale?: string; // e.g., 'en_US', 'ar_SA'
};
}
One critical detail most teams miss: WhatsApp can deliver the same webhook twice during network retries. Without deduplication on messageId, your bot may process a user's "Confirm Order" message twice — leading to duplicate orders, double charges, or broken state. Always persist processed message IDs in a fast store like Redis with a 24-hour TTL.
Layer 2: Conversation State Machine
This is the most underengineered piece in almost every WhatsApp chatbot workflow we've audited. Most teams use a flat currentStep string in a database row. That works for three steps. It falls apart at thirty.
The correct model is a hierarchical finite state machine (HFSM). Each conversation is a state machine instance. States can be nested (e.g., a "Checkout" parent state containing "SelectAddress", "ConfirmItems", "Payment" child states). Transitions are triggered by intents, not raw text.
// Simplified state machine definition (XState-style pseudocode)
const checkoutMachine = createMachine({
id: 'checkout',
initial: 'selectAddress',
states: {
selectAddress: {
on: {
ADDRESS_SELECTED: 'confirmItems',
HELP_REQUESTED: '#root.humanHandoff',
TIMEOUT: 'abandoned'
}
},
confirmItems: {
on: {
CONFIRMED: 'payment',
EDIT_REQUESTED: 'selectAddress',
CANCEL: 'cancelled'
}
},
payment: {
on: {
PAYMENT_SUCCESS: 'complete',
PAYMENT_FAILED: 'paymentRetry',
MAX_RETRIES_EXCEEDED: '#root.humanHandoff'
}
},
complete: { type: 'final' },
cancelled: { type: 'final' },
abandoned: { type: 'final' }
}
});
Using a proper state machine library (we recommend XState for Node.js environments) gives you serializable state — meaning you can persist the entire machine snapshot to Redis or PostgreSQL and restore it exactly when the user replies 6 hours later. This is what enables truly stateful, multi-session WhatsApp chatbot workflows.
Layer 3: Intent Resolution — Where NLP Meets Routing
Raw user input needs to be classified into intents before it touches your state machine. The architecture decision here is critical: rule-based vs. ML-based vs. hybrid.
For most business WhatsApp chatbot workflows, a hybrid approach delivers the best results:
- Exact/pattern matching handles interactive button replies and list selections (these are structured payloads — no NLP needed)
- Keyword + regex rules handle high-confidence, high-frequency intents (e.g., "cancel", "refund", "track order")
- Small fine-tuned classifier (e.g., a distilled BERT model or OpenAI function-calling) handles ambiguous free-text inputs
- LLM fallback handles truly open-ended queries with a context-aware prompt
This tiered approach means 70–80% of messages never touch the LLM, keeping your median response latency under 180ms for structured flows, while still handling natural language gracefully. When we implemented this architecture in AI Greentick — our WhatsApp Business Automation platform — we saw a 62% reduction in LLM API costs compared to routing everything through GPT-4, with zero measurable drop in user satisfaction scores.
Designing WhatsApp Chatbot Workflows for Real Human Behavior
The biggest gap between demo bots and production bots is accounting for how humans actually communicate on WhatsApp. Here are the patterns that will break your workflow if you haven't planned for them:
1. Mid-Flow Context Switches
A user is 3 steps into placing an order and suddenly asks "what's your return policy?" Your bot must handle this as a contextual detour — answer the question and then offer to resume exactly where they left off, not restart the flow. This requires a conversation stack, not just a single current state.
2. Implicit Confirmations and Negations
Users don't say "Yes, I confirm." They say "yep", "sure", "ok fine", "yeah go ahead", "nah", "not really", "actually no". Your intent classifier needs a robust confirmation/negation model, and it needs to be context-aware — "no" means something different in a payment confirmation versus a "would you like to hear more?" prompt.
3. Session Abandonment and Re-entry
Users abandon conversations constantly. Your workflow must define a clear timeout strategy per state:
- Soft timeout (e.g., 30 minutes): Send a gentle re-engagement message ("Still there? Your cart is saved 🛒")
- Hard timeout (e.g., 24 hours): Expire the session, archive the state, and greet the user fresh on next contact
- Re-entry detection: If a user returns within the soft window, restore state and ask if they want to continue
4. Language and Locale Switching
In markets like India, the Middle East, or Southeast Asia, users frequently switch languages mid-conversation. Your NLP layer must detect language per message, not per session. Store the detected locale on each turn and use the most recent confident detection for response generation.
Human Handoff: The Feature That Determines Your CSAT Score
No matter how intelligent your WhatsApp chatbot workflows are, some conversations need a human. The quality of your handoff protocol is often the single biggest driver of customer satisfaction.
A production-grade handoff must:
- Detect escalation triggers — explicit requests ("talk to agent"), repeated failed intents (3+ consecutive low-confidence classifications), negative sentiment detection, or high-value transaction thresholds
- Preserve full conversation context — the agent must see the entire conversation history, the user's current state in the workflow, and any data already collected (name, order ID, issue type)
- Queue and notify — place the conversation in an agent queue, send the user an estimated wait time, and notify the assigned agent via your support dashboard
- Resume gracefully — when the agent resolves the issue and closes the ticket, the bot can re-engage with a follow-up satisfaction survey or re-enter a post-support workflow
In AI Greentick, we built this handoff layer as a first-class feature — not an afterthought. Agent context panels show a real-time state machine visualization so support staff immediately understand where the bot left off, reducing average handle time by 38% in pilot deployments.
Scaling WhatsApp Chatbot Workflows to Millions of Sessions
Architecture that works at 1,000 daily active sessions will not survive 1,000,000. Here's what changes at scale:
Session Store: Redis Cluster with Consistent Hashing
At scale, your session store becomes the hottest component. Use Redis Cluster with consistent hashing to distribute session keys across nodes. Set appropriate TTLs, use Lua scripts for atomic state transitions (read-modify-write must be atomic to prevent race conditions when users send rapid messages), and implement a circuit breaker for Redis unavailability.
Webhook Processing: Queue-Based Decoupling
Never process WhatsApp webhook payloads synchronously in your HTTP handler. The handler must acknowledge the webhook within 200ms (WhatsApp's timeout), then push the message onto a queue (SQS, RabbitMQ, or Kafka depending on your throughput requirements) for async processing. This architecture absorbs traffic spikes without dropping messages.
// Webhook handler — acknowledge immediately, queue for processing
app.post('/webhook/whatsapp', async (req, res) => {
// 1. Validate webhook signature (HMAC-SHA256)
if (!validateSignature(req)) return res.sendStatus(403);
// 2. Acknowledge to WhatsApp immediately
res.sendStatus(200);
// 3. Push to processing queue (non-blocking)
await messageQueue.publish('whatsapp.inbound', {
raw: req.body,
receivedAt: Date.now()
});
});
Horizontal Scaling of Workers
Your message processing workers are stateless (state lives in Redis/DB), so they scale horizontally without coordination. Use per-session message ordering guarantees — partition your queue by sessionId (phone number hash) so messages from the same user are always processed in order, even under high load.
Observability: The Metrics That Matter
For production WhatsApp chatbot workflows, instrument these metrics as a baseline:
- Intent classification latency (p50, p95, p99) — target p95 < 300ms for hybrid classifier
- Workflow completion rate per flow type — track where users drop off
- Fallback rate — percentage of messages hitting the LLM fallback (high fallback = poor rule coverage)
- Human handoff rate — by intent category, to identify automation gaps
- Session re-entry rate — users who abandoned and returned (signals friction in your flow)
- End-to-end message latency — from webhook receipt to response delivered (target p95 < 2 seconds)
What We've Learned Building AI Greentick
Building AI Greentick — a production WhatsApp Business Automation platform — forced us to solve every one of these problems at scale, not in theory. A few hard-won lessons:
- Start with flows, not AI. Map your top 10 user intents manually before touching an LLM. Most business conversations are highly predictable — structured flows will handle 80% of volume.
- Share this article:WhatsApp AutomationApargo Lab
Related Articles
Explore more insights from our engineering and product teams.

How to Verify Documents Online and Detect Fake, Forged, or AI-Generated Files
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly with VerifyDocs. Secure, fast, and AI-powered fraud detection.
Online Document Verification: Detect Fake, Edited & AI-Generated Files Instantly
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly using VerifyDocs. Fast, secure, and AI-powered.
Online Document Verification: Detect Fake, Edited & AI-Generated Files Instantly
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly using VerifyDocs. Fast, secure, and AI-powered.