
Blogs
Build Better Products with Insights & Inspiration.
Practical insights and real stories to guide your product from vision to reality.

AI Gateway Rate Limiting: How to Protect Your LLM APIs From Abuse, Cost Explosions, and Cascading Failures in Production
Running LLM APIs in production without a proper AI gateway rate limiting strategy is a ticking cost bomb. Learn how to architect intelligent throttling, quota management, and abuse prevention that keeps your AI infrastructure fast, fair, and financially sane.
Database Connection Pooling: How to Eliminate Bottlenecks and Scale Your Backend to Handle 10x Traffic Without Rewriting a Single Query
Most backends don't collapse under load because of bad queries — they collapse because of exhausted database connections. Learn how to architect database connection pooling correctly and unlock massive throughput gains without touching your SQL.

WebSocket Load Balancing: How to Distribute Millions of Persistent Connections Without Dropping a Single Message
Most load balancers silently destroy WebSocket connections at scale — here's the complete engineering playbook to architect sticky sessions, horizontal scaling, and zero-drop message delivery for production real-time systems.
Kubernetes Secret Management: How to Stop Leaking Credentials Before They Burn Down Your Production Environment
Most teams treat Kubernetes secrets like an afterthought — until credentials leak, infrastructure burns, and the post-mortem is brutal. Here's the engineering playbook to do it right.
Service Mesh Observability: How to Gain Full Visibility Into Your Microservices Traffic Without Drowning in Noise
Most engineering teams deploy a service mesh and assume they have observability — they don't. This deep-dive shows you exactly how to instrument, correlate, and act on service mesh telemetry to catch failures before your users do.
Retrieval Augmented Generation Evaluation: How to Measure, Debug, and Continuously Improve Your RAG Pipeline in Production
Most RAG systems feel great in demos and silently degrade in production. Learn the exact evaluation frameworks, metrics, and debugging strategies senior engineers use to keep RAG pipelines accurate, fast, and trustworthy at scale.
OpenTelemetry Distributed Tracing: How to Instrument Your Entire Stack and Eliminate Blind Spots in Production
Most engineering teams only discover production failures after users complain — OpenTelemetry distributed tracing changes that by giving you deep, correlated visibility across every service, database call, and API hop in your system.
Distributed Cache Invalidation: How to Keep Your Data Fresh Across Every Node Without Blowing Up Your System
Cache invalidation is one of the hardest problems in distributed systems — get it wrong and your users see stale data, race conditions, or cascading failures. This deep-dive shows you exactly how to architect bulletproof distributed cache invalidation strategies that scale.
AI Memory Architecture: How to Build LLM Applications That Actually Remember Context Across Sessions
Most LLM apps forget everything the moment a session ends — and that's killing user experience. Learn how to engineer a robust AI memory architecture that gives your language models persistent, scalable, and intelligent recall across every conversation.
LLM Fine-Tuning vs RAG: How to Choose the Right Knowledge Strategy for Your Production AI Application
Choosing between LLM fine-tuning and RAG can make or break your AI product's accuracy, cost, and maintainability. This deep-dive breaks down both architectures with real benchmarks, decision frameworks, and production-grade implementation patterns.
Canary Deployment Strategy: How to Roll Out Features Safely to Production Without Gambling Your Entire User Base
Canary deployment strategy is the engineering safety net that separates teams who ship fearlessly from those who pray before every release. Learn how to architect, automate, and monitor progressive rollouts that catch failures before they become catastrophes.

WebAssembly WASM Performance: How to Unlock Near-Native Speed in the Browser Without Rewriting Your Entire Stack
WebAssembly WASM performance is redefining what's possible in browser-based applications — learn how to integrate WASM modules into production web apps, squeeze out sub-millisecond execution, and deploy compute-heavy logic without abandoning your existing JavaScript stack.
AI Agent Orchestration: How to Build Multi-Agent Systems That Actually Work in Production
Multi-agent AI systems promise autonomous reasoning and task delegation — but most teams ship them broken. This deep-dive shows you exactly how to architect production-grade AI agent orchestration that's reliable, observable, and cost-efficient.
Progressive Web App Performance: How to Engineer PWAs That Feel Native, Load Instantly, and Outperform the App Store
Progressive Web Apps are no longer a compromise — when engineered correctly, they out-load, out-engage, and out-convert native apps. Here's the complete technical playbook to build PWAs that perform at production scale.
WebSocket vs Server-Sent Events: How to Choose the Right Real-Time Protocol for Your Production Application
Choosing between WebSocket vs Server-Sent Events can make or break your real-time feature's performance, scalability, and cost. This deep-dive breaks down the architecture, trade-offs, and exact use cases so your engineering team ships the right solution the first time.
WebSocket Connection Pooling: How to Handle Millions of Concurrent Real-Time Connections Without Melting Your Infrastructure
Most teams bolt WebSockets onto existing HTTP infrastructure and wonder why everything collapses at 10,000 concurrent users. This deep-dive shows you exactly how to architect WebSocket connection pooling at scale — with real numbers, battle-tested patterns, and code you can ship today.
OAuth 2.0 Token Security: How to Harden Your Authentication Layer and Stop Token Theft Before It Destroys Your Platform
Token-based auth is the backbone of every modern API — but most teams ship OAuth 2.0 implementations riddled with silent vulnerabilities. This deep-dive shows you exactly how to lock down your authentication layer before attackers exploit it.
Prompt Injection Attack Defense: How to Secure Your LLM-Powered Applications Before Attackers Hijack Your AI
Prompt injection attacks are the fastest-growing threat vector in LLM-powered applications — and most teams don't even know they're exposed. This deep-dive engineering guide shows you exactly how to detect, prevent, and architect your way out of prompt injection vulnerabilities before they take down your AI product.
WebRTC Peer-to-Peer Streaming: How to Build Ultra-Low Latency Real-Time Communication Without a Media Server Bottleneck
Discover how to architect WebRTC peer-to-peer streaming for production-grade real-time communication — from ICE negotiation and STUN/TURN infrastructure to scalable mesh topologies — all without a centralized media server eating your bandwidth and budget.
gRPC vs REST API Performance: How to Choose the Right Protocol for High-Throughput Production Systems
Still defaulting to REST for every microservice? This deep-dive into gRPC vs REST API performance reveals when each protocol wins, with real latency benchmarks, architecture patterns, and migration strategies for production-grade systems.
Feature Flag Architecture: How to Ship Code Daily Without Turning Production Into a Minefield
Feature flags are no longer just on/off switches — they're the backbone of modern continuous delivery. Learn how to architect a production-grade feature flag system that lets your team ship daily, run experiments, and kill bad releases in milliseconds.
Async Job Queue Architecture: How to Build a Resilient Background Processing System That Never Loses a Task
Background jobs are the silent backbone of every high-scale product — and most teams architect them wrong until something breaks in production. This deep-dive covers everything you need to build a bulletproof async job queue architecture that handles failures, retries, and millions of tasks without dropping a single one.
Multi-Region Database Replication: How to Build a Globally Distributed Data Layer That Stays Consistent, Fast, and Fault-Tolerant
Multi-region database replication is the backbone of every high-availability global product — but most teams get it catastrophically wrong. Learn the exact architecture patterns, conflict resolution strategies, and latency trade-offs that elite engineering teams use to build data layers that never go down.
LLM Observability Monitoring: How to See Inside Your AI Models Before They Quietly Break Production
Most teams deploy LLMs and hope for the best — until hallucinations, latency spikes, and silent failures erode user trust. This deep-dive shows you exactly how to instrument, trace, and monitor LLMs in production with real engineering precision.
CI/CD Pipeline Security: How to Harden Your Deployment Workflow and Ship Code Without Handing Attackers the Keys
Your CI/CD pipeline is the most powerful—and most dangerous—system in your infrastructure. Learn how elite engineering teams lock down every stage of the deployment workflow to ship fast without exposing secrets, credentials, or production environments to attackers.
GraphQL Federation Architecture: How to Unify Distributed APIs Into a Single Supergraph Without Losing Your Mind
GraphQL Federation Architecture lets you compose multiple independent GraphQL services into one powerful supergraph — here's the complete engineering playbook to do it right, at scale, in production.
WebAssembly Edge Deployment: How to Run Near-Zero Latency Applications at the Network Edge Without Rebuilding Your Stack
WebAssembly edge deployment is rewriting the rules of low-latency computing — discover how engineering teams are shipping sandboxed, polyglot workloads to the network edge in milliseconds, slashing cloud egress costs, and eliminating cold starts without touching their core infrastructure.
Event-Driven Architecture Microservices: How to Build Loosely Coupled Systems That Scale Without Breaking
Discover how to design and implement event-driven architecture for microservices that stay loosely coupled, highly resilient, and infinitely scalable — with real patterns, code, and hard-won engineering lessons from production systems.
Kubernetes Auto-Scaling Strategies: How to Build a Self-Healing, Cost-Efficient Infrastructure That Scales Without Human Intervention
Discover the engineering playbook behind production-grade Kubernetes auto-scaling — from HPA and VPA to KEDA and cluster autoscaler — and learn how to build infrastructure that dynamically adapts to traffic spikes, slashes cloud costs by up to 60%, and never pages your on-call engineer at 3 AM.
Distributed Tracing Observability: How to Debug Production Systems at Scale Before Your Users Notice
Modern distributed systems fail in ways that logs alone can never explain. Learn how to implement distributed tracing observability across microservices to catch latency spikes, silent failures, and cascading errors before they become customer-facing incidents.
Serverless Cold Start Optimization: How to Eliminate Latency Spikes and Keep Your Functions Blazing Fast in Production
Cold starts are silently killing your serverless application's user experience — adding 800ms to 4 seconds of invisible latency on every new invocation. This deep-dive engineering guide shows you exactly how to diagnose, architect around, and eliminate cold start penalties across AWS Lambda, Google Cloud Functions, and Azure Functions.
Database Schema Migration: How to Evolve Your Production Database Without Fear, Downtime, or Data Loss
Database schema migrations are the silent killer of production deployments — one wrong ALTER TABLE can lock your entire database for minutes. Learn the battle-tested engineering playbook Apargo uses to ship schema changes safely, at scale, with zero downtime.
API Rate Limiting Strategies: How to Protect Your Backend Without Throttling Your Best Users
Most teams implement rate limiting as an afterthought — and pay for it with cascading failures, abuse incidents, and frustrated power users. This deep-dive covers the engineering patterns, algorithms, and tiered strategies that protect your infrastructure while keeping your best customers fast.

Edge Computing AI Inference: How to Run Low-Latency ML Models Without the Cloud Tax
Discover how edge computing AI inference is reshaping real-time ML deployments — slashing latency below 20ms, eliminating cloud egress costs, and enabling always-on intelligence at the device level. A deep engineering guide from the team at Apargo.
Micro-Frontend Architecture: How to Scale Large Web Applications Without Killing Your Engineering Team
Micro-frontend architecture is the missing playbook for teams struggling to scale monolithic React or Angular apps. Learn how to decompose, deploy, and orchestrate independently shippable frontend modules in production.
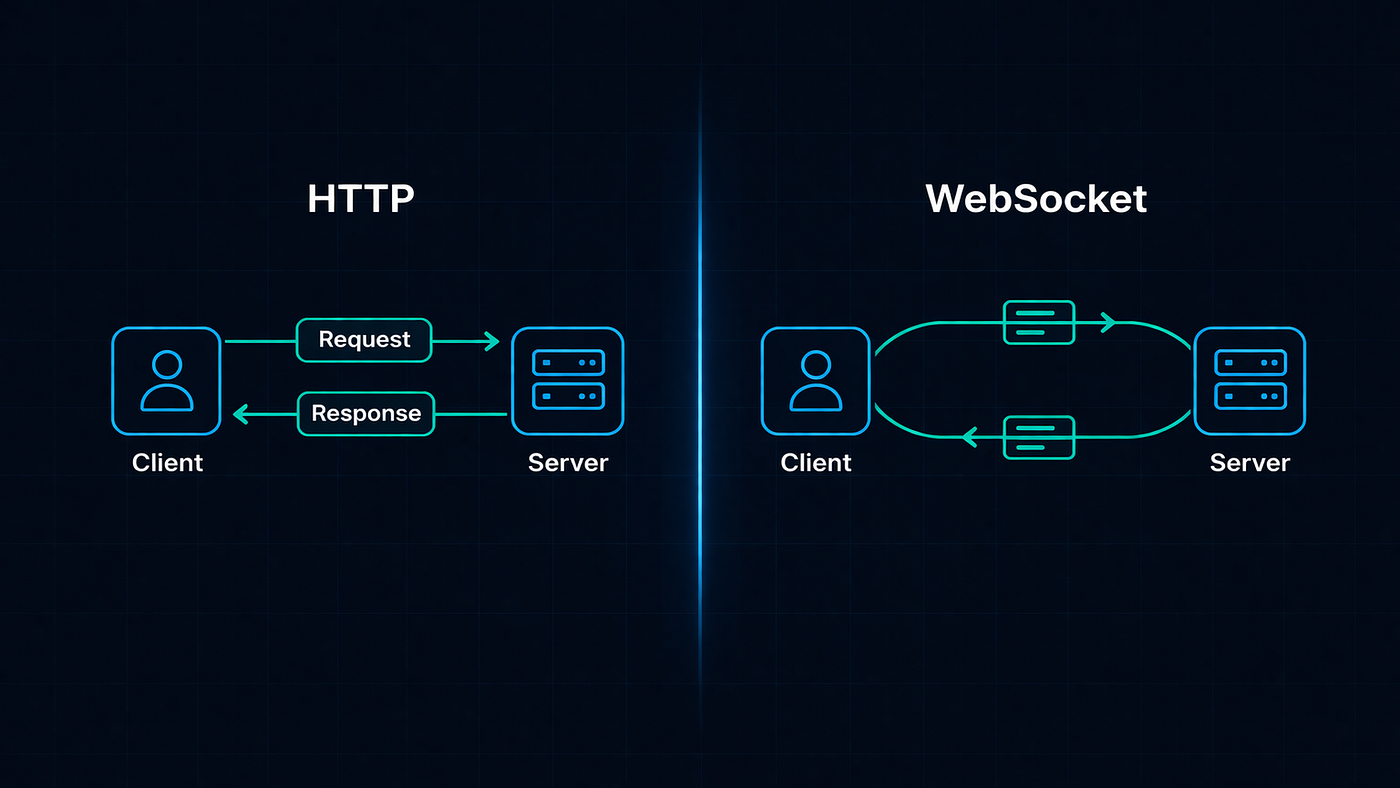
WebSocket Real-Time Architecture: How to Build Scalable Live Features Without Breaking Your Backend
Real-time features are no longer a luxury — they're a product expectation. Learn how to architect WebSocket-based systems that scale to hundreds of thousands of concurrent connections without melting your infrastructure.
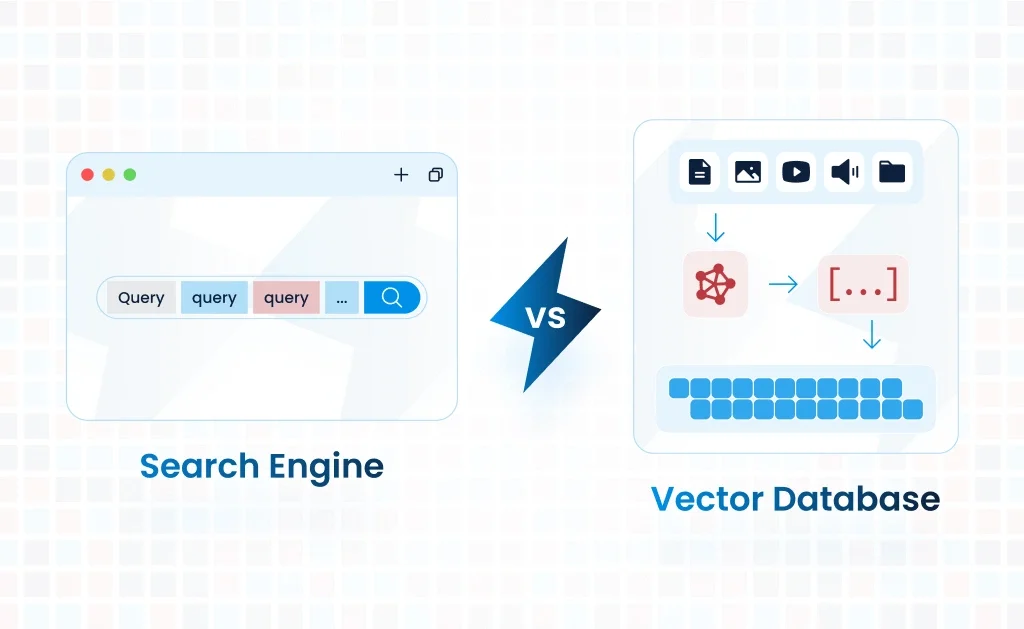
Vector Database Selection: How to Choose the Right Engine for Production AI Applications
Choosing the wrong vector database can silently kill your AI product's performance, scalability, and cost-efficiency. This deep-dive guide breaks down every major vector database option, benchmarks, and architectural trade-offs so your engineering team can make the right call before writing a single line of production code.
Zero Downtime Deployments: The Engineering Playbook Every Scaling Team Needs
Shipping code without dropping a single request sounds impossible — until you understand the exact patterns, tools, and sequencing that elite engineering teams use. This is the definitive playbook for zero downtime deployments at scale.

React Native vs Swift/Kotlin in 2025: How to Pick the Right Mobile Stack for Your Product
Choosing between React Native and native Swift/Kotlin can make or break your mobile product's performance, scalability, and time-to-market. This deep-dive breaks down the real engineering trade-offs so you can decide with confidence.

Production LLM Cost Optimization: How to Cut AI Inference Bills by 70% Without Sacrificing Quality
Running LLMs in production is brutally expensive — unless you know exactly where the waste is. This deep-dive covers battle-tested Production LLM Cost Optimization strategies that slash inference bills while keeping response quality razor-sharp.
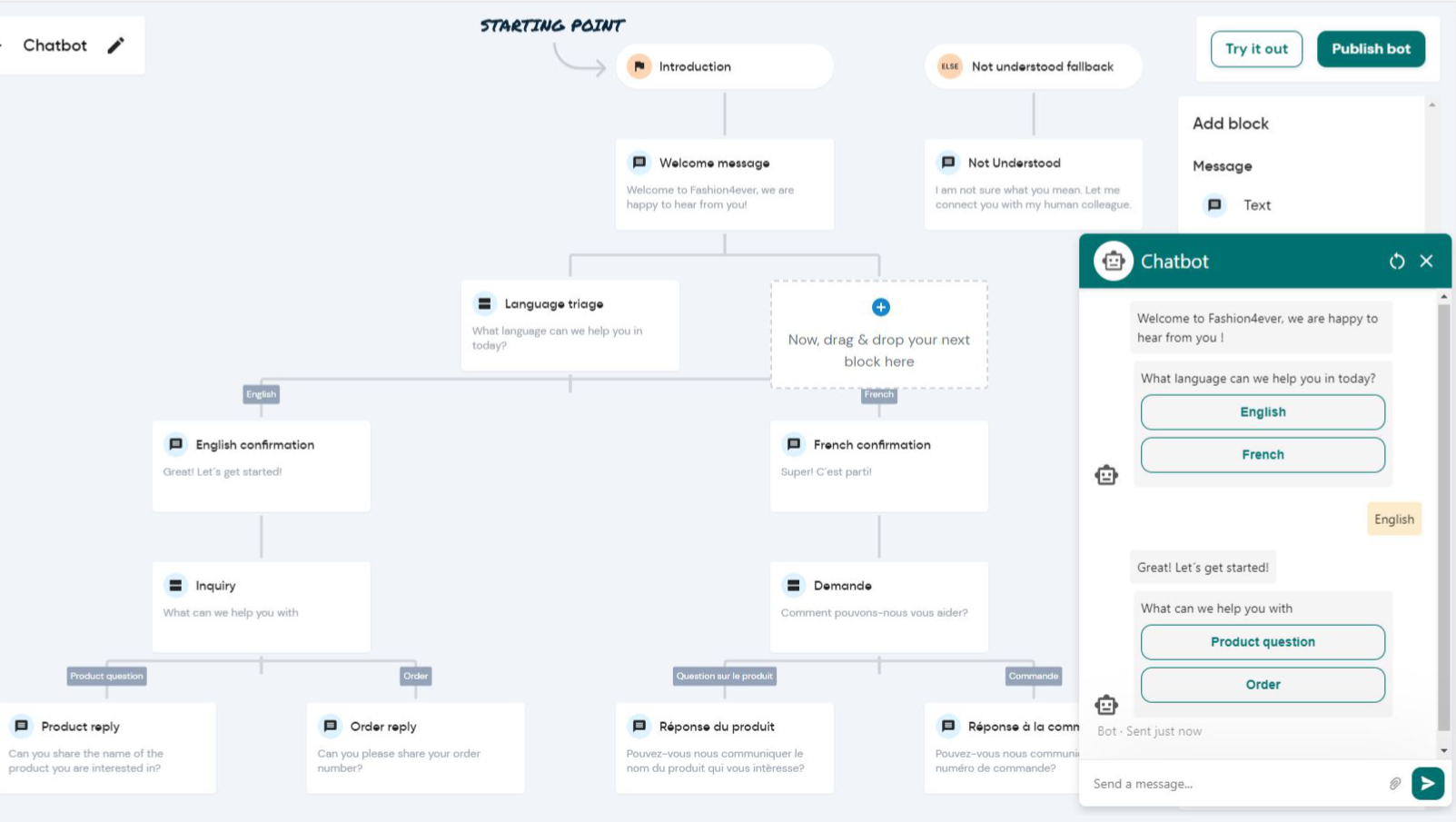
WhatsApp Chatbot Workflows: How to Architect Intelligent Automation That Scales to Millions of Conversations
Most WhatsApp chatbots fail not because of bad AI — but because of poorly designed conversation workflows. This deep-dive shows you exactly how to architect WhatsApp chatbot workflows that handle real-world complexity, scale to millions of sessions, and actually convert.

Multi-Tenant SaaS Architecture: How to Build Scalable Isolation Without Killing Performance
Building a multi-tenant SaaS platform that scales without compromising data isolation, latency, or cost efficiency is one of the hardest engineering challenges. Here's the complete architecture playbook.

How we decide what to build first
A deep dive into our prioritization framework, balancing immediate client requests with long-term architectural scalability.

Where AI actually saves teams time
Beyond the hype: real-world case studies of implementing LLM workflows and automated pipelines that cut development cycles by 40%.

How AI-Driven Workflows Are Transforming Product Development
Discover smarter ways to ideate, design, and build using AI tools.
Why Fast Apps Win: The Blueprint for Lightning-Quick Experiences
Explore proven strategies to boost speed and delight users every time.

Design Smarter: How User Behavior Shapes Winning Products
Learn how to discover what users truly want and build with confidence.

Lessons from running our own SaaS
The operational, technical, and marketing takeaways from scaling AI Greentick to handle millions of WhatsApp messages daily.

Product KPIs That Actually Matter And How to Track Them
Measure progress the right way to build momentum and stay focused.

Nail Your First Launch: A Checklist for Product Debut Success
Avoid common launch traps and create excitement from day one.

Scaling Design the Right Way with a Solid Component System
Build consistency, save time, and ship optimized UI every release.
Top 10 Ways to Detect Fake Documents Online (Complete Guide)
Discover the top 10 ways to detect fake, forged, edited, or AI-generated documents online. Learn expert tips and use VerifyDocs for instant verification.
Online Document Verification: Detect Fake, Edited & AI-Generated Files Instantly
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly using VerifyDocs. Fast, secure, and AI-powered.
Online Document Verification: Detect Fake, Edited & AI-Generated Files Instantly
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly using VerifyDocs. Fast, secure, and AI-powered.
How to Verify Documents Online and Detect Fake, Forged, or AI-Generated Files
Learn how to verify documents online and detect fake, forged, edited, or AI-generated files instantly with VerifyDocs. Secure, fast, and AI-powered fraud detection.
Verify Documents Online – Detect Fake, Forged & AI-Generated Files Instantly
VerifyDocs helps you detect fake, forged, edited, or AI-generated documents instantly. Upload PDFs, images, and certificates for fast online verification and fraud detection.